Результаты практической работы "Поиск решения":
Откройте рабочую книгу "Решение уравнений методом подбора параметра" и загрузите себе копию.
Откройте рабочую книгу "Поиск решения" и загрузите себе копию.
По большому счету, можно выделить две группы методов решения любых задач:
Где находится «Подбор параметра»?


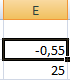
|
Фамилия, имя
|
Оценка
|
|
Макрушина
|
7
|
|
Искендеров, Листопад
|
??
|
|
Ростовцева, Горбатенко
|
??
|
|
Кучерявенко
|
9
|
|
Лисняк, Познанский
|
7
|
|
Яценко, Шилкова
|
8
|
|
Куприенко, Ковалёв
|
8
|
|
Ужва, Савенкова, Капуста
|
9
|
|
Болгарова
|
8
|
|
Зима Ищенко Кудряшова
|
11
|
|
Куц, Терещенко
|
9
|
|
Кобзева, Мажара
|
7
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Откройте рабочую книгу "Решение уравнений методом подбора параметра" и загрузите себе копию.
Откройте рабочую книгу "Поиск решения" и загрузите себе копию.
Что такое метод перебора?
Алгебраические методы
|
Численные методы
|
За небольшой отрезок сразу получается точный ответ
|
Сводят задачи к перебору вариантов
|
Применимы лишь к небольшому числу не очень сложных задач.
|
Дают результат в виде числового значения с погрешностью
|
Существует класс задач, которые легче решить методом перебора, чем методом «научного тыка». Инструмент Подбор параметра помогает решить задачу, когда известно, что должно получиться в ответе, но не известно, какое значение должна иметь одна из переменных. Говоря простым математическим языком, мы ищем решение уравнения с одним неизвестным.
Подбор параметра в Excel и примеры его использования
«Подбор параметра» - ограниченный по функционалу вариант надстройки «Поиск решения». Это часть блока задач инструмента «Анализ «Что-Если».
В упрощенном виде его назначение можно сформулировать так: найти значения, которые нужно ввести в одиночную формулу, чтобы получить желаемый (известный) результат.
Где находится «Подбор параметра»?
Известен результат некой формулы. Имеются также входные данные. Кроме одного. Неизвестное входное значение мы и будем искать. Рассмотрим функцию «Подбор параметра» в Excel на примере.
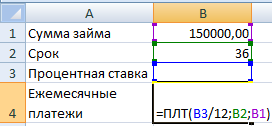
Необходимо подобрать процентную ставку по займу, если известна сумма и срок. Заполняем таблицу входными данными.
Процентная ставка неизвестна, поэтому ячейка пустая. Для расчета ежемесячных платежей используем функцию ПЛТ.
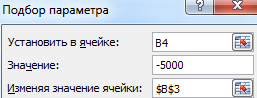
Когда условия задачи записаны, переходим на вкладку «Данные». «Работа с данными» - «Анализ «Что-Если» - «Подбор параметра».
В поле «Установить в ячейке» задаем ссылку на ячейку с расчетной формулой (B4). Поле «Значение» предназначено для введения желаемого результата формулы. В нашем примере это сумма ежемесячных платежей. Допустим, -5 000 (чтобы формула работала правильно, ставим знак «минус», ведь эти деньги будут отдаваться). В поле «Изменяя значение ячейки» - абсолютная ссылка на ячейку с искомым параметром ($B$3).
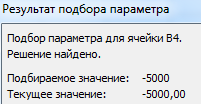
После нажатия ОК на экране появится окно результата.
Чтобы сохранить, нажимаем ОК или ВВОД.
Функция «Подбор параметра» изменяет значение в ячейке В3 до тех пор, пока не получит заданный пользователем результат формулы, записанной в ячейке В4. Команда выдает только одно решение задачи.
Решение уравнений методом подбора параметров
Функция «Подбор параметра» идеально подходит для решения уравнений с одним неизвестным.
Возьмем для примера выражение:
20 * х – 20 / х = 25.
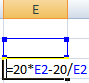
Аргумент х – искомый параметр. Пусть функция поможет решить уравнение подбором параметра и отобразит найденное значение в ячейке Е2.
В ячейку Е3 введем формулу:
= 20 * Е2 – 20 / Е2.
А в ячейку Е2 поставим любое число, которое находится в области определения функции. Пусть это будет 2.
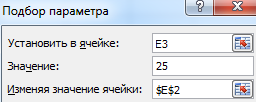
Запускаем инструмент и заполняем поля:
- «Установить в ячейке» - Е3 (ячейка с формулой);
- «Значение» - 25 (результат уравнения);
- «Изменяя значение ячейки» - $Е$2 (ячейка, назначенная для аргумента х).
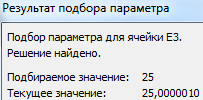
Результат функции:
Найденный аргумент отобразится в зарезервированной для него ячейке.
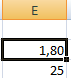
Решение уравнения: х = 1,80.
Функция «Подбор параметра» возвращает в качестве результата поиска первое найденное значение. Вне зависимости от того, сколько уравнение имеет решений. Если, например, в ячейку Е2 мы поставим начальное число -2, то решение будет иным.
Функция «Подбор параметра» работает правильно, если:
- Значение желаемого результата выражено формулой;
- Все формулы написаны полностью и без ошибок.
Надстройка "Поиск решения" и подбор нескольких параметров в Excel
Надстройка Excel «Поиск решения» – это аналитический инструмент, который позволяет нам быстро и легко определить, когда и какой результат мы получим при определенных условиях. Возможности инструмента поиска решения намного выше, чем может предоставить «подбор параметра» в Excel.
Основные отличия между поиском решения и подбором параметра:
- Подбор нескольких параметров в Excel.
- Наложение условий ограничивающих изменения в ячейках, которые содержат переменные значения.
- Возможность использования в тех случаях, когда может быть много решений одной задачи.
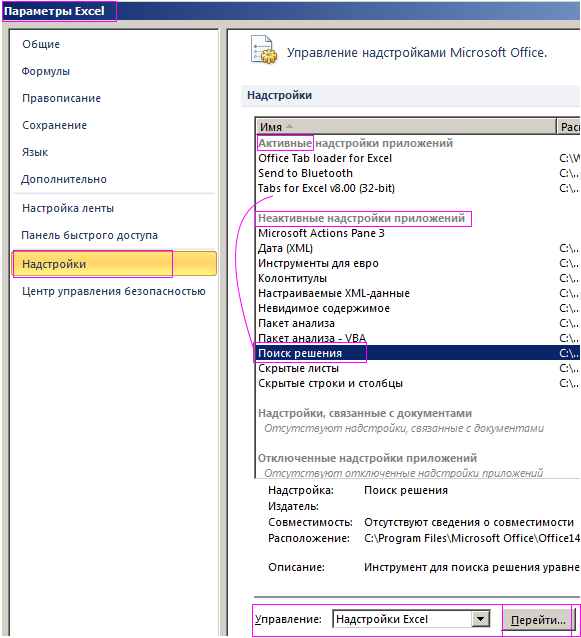
Подключение надстройки «Поиск решения»
В меню Office выбрать «Параметры Excel» и перейти на вкладку «Надстройки». Здесь будут видны активные и неактивные, но доступные надстройки.
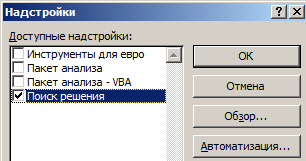
Если нужная надстройка неактивна, то нужно перейти по ссылке «Управление» (внизу таблички) и установить надстройку. Появится диалоговое окно, в котором нужно отметить галочкой «Поиск решения» и нажать ОК.
Теперь на простенькой задаче рассмотрим, как пользоваться расширенными возможностями Excel.
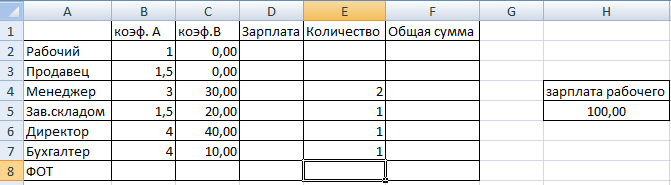
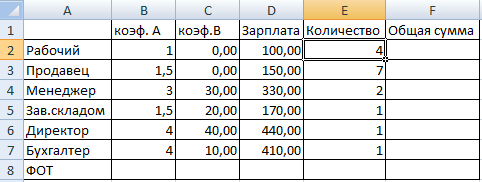
Для нормальной работы небольшого предприятия хватит 4-6 рабочих, 7-9 продавцов, 2 менеджера, заведующий складом, бухгалтер, директор. Нужно определить их оклады.
Ограничения: месячный фонд зарплаты минимальный; оклад рабочего – не ниже прожиточного минимума в 100 долларов. Коэффициент А показывает: во сколько раз оклад специалиста больше оклада рабочего.
Таблица с известными параметрами:
- менеджер получает на 30 долларов больше продавца (см. коэффициент В);
- заведующий складом – на 20 долларов больше рабочего;
- директор – на 40 долларов больше менеджера;
- бухгалтер – на 10 долларов больше менеджера.
Найдем зарплату для каждого специалиста (на рисунке все понятно).
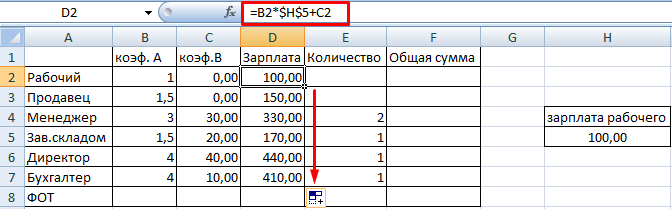
Переходим на вкладку «Данные» - «Анализ» - «Поиск решения» (так как мы добавили надстройку, теперь она доступна).
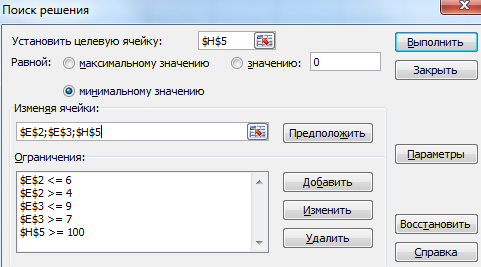
Заполняем меню. Чтобы вводить ограничения, используем кнопку «Добавить». Строка «Изменяя ячейки» должна содержать ссылки на те ячейки, для которых программа будет искать решения. Заполненный вариант будет выглядеть так:
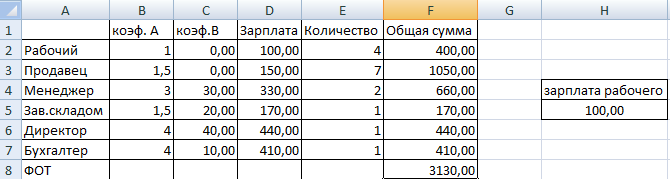
Нажимаем кнопку «Выполнить» и получаем результат:
Теперь мы найдем зарплату для всех категорий работников и посчитаем ФОТ (Фонд Оплаты Труда).